Context
- Distributed systems will fail.
- Things gets complicated as the data requirements / scale increases.
- It’s about how your system responds to partial failures and spikes.
- Fault is an incorrect internal state in your system.
- Failure is an inability of the system to perform its intended job, eventually means loss of uptime and availability on systems.
- Faults if not contained from propagating, can lead to failures.

Transactions
Transactions by old school definition should be ACID complaint (All or nothing) and this is really hard to achieve in distributed systems, given lot of moving parts and high probability of failures.
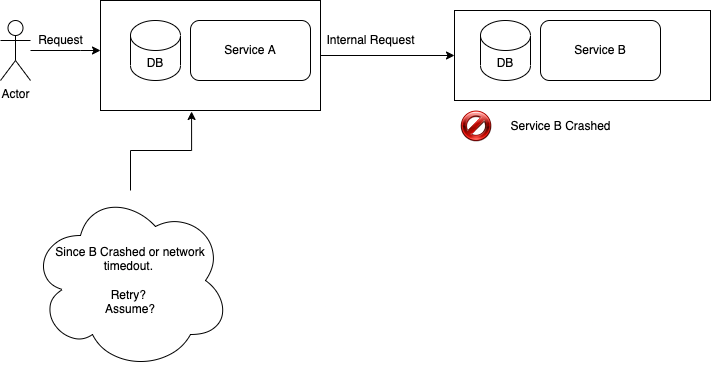
In the above example, once service B crashes or network times out, there is no easy way for A to make the next decision. It’s harder if request from user is supposed to be atomic; for example payments and orders.
Probable Solutions
There are handful of options at this point.
2 PC Transactions

Unless traffic patterns are consistent and apps can tolerate failures or restarts please avoid these.
Pros:
- Very simple to implement for caller
Cons:
- Breaks service level encapsulations as cross DB coordination is required.
- Performance issues due to network coordination and locks.
- Can block and stop the world if coordinator is down.
- Deadlocks 🙁
Sagas
“A saga is a sequence of transactions that updates each service and publishes a message or event to trigger the next transaction step. If a step fails, the saga executes compensating transactions that counteract the preceding transactions”

While Saga or (Domain) event driven solves transaction management they come with other set of challenges like :
- Atomicity around DB commits and Queue publishes.
- Database commit rollback must cause rollback on queue. (Without 2PC its hard to do)
- Successful DB Commit must publish to queue. (Retires is only option, monitoring can reduce MTTD)
- Compensating transactions.
- Culture / process updates around idempotency / retries and building for failures.
CDC Outbox pattern
CDC or change data capture systems works on connecting to database write ahead logs and using them for propagating changes using queue systems such as Kafka. They work on same principle as database replica, connecting and interpreting each statement log.
Given high consistent nature of this data, its mostly used in data engineering for creating warehouses / lakes etc. They also present a great way of generating event stream outside a service with high consistency. Using a broker such as Kafka also allows durability, multiple consumers and replayability allowing new consumers / extensions.
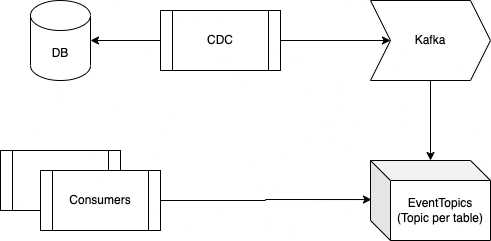
For any Domain level updates service along with update can also insert a event blob object in a different table. This table becomes event propagation source via CDC and is available on separate topic on Kafka.
Consider below classes for payment and another carrying Domain event on change of payment status or something downstream apps might be interested in.
class Payment {
private Long id;
private String externalId;
private BigDecimal amount;
// Skipped rest for brevity
}
class PaymentEvent {
private BigDecimal amount;
private String paymentStatus; // Complted / Pending / Failed
private String externalId;
}
.
Now we publish domain update and outgoing event (hence outbox) to a dummy table within the same transaction.
@Transactional
void process(Payment payment) {
PaymentEvent paymentEvent = new PaymentEvent(payment);
entityManager.persist(payment);
entityManager.persist(paymentEvent);
}
.
Since these “events” are propagated via append-only logs, we can also delete the event once its committed, since it would be triggered as two different events on Kafka; INSERT and DELETE.
Consumers can ignore delete and only filter INSERTs, or a connector can probably republish.
Anyways, above transaction would ensure both payment and paymentEvent are persisted atomically while the event now thanks to CDC pipeline is available for applications to consume; thus providing best of both worlds [Atomic transactions and Async queues of distributed systems].
0 Comments